
Data deduplication using BigQuery
Deduplicating Data in BigQuery: Using QUALIFY for Clean, Unique Data.

Introduction
If you've worked with data for a while, you know that duplicates are almost unavoidable, especially when dealing with multiple data sources. Cleaning up these duplicates is a critical step in ensuring accurate analysis. In this post, I’ll show you how to deduplicate data in BigQuery using the QUALIFY clause, along with a quick mention of how to achieve the same with ROW_NUMBER.
Why BigQuery?
Honestly? Because it’s what I’ve used the most during my career. It’s fast, handles large datasets effortlessly, and fits right into the Google Cloud ecosystem. Plus, features like QUALIFY make repetitive tasks like deduplication easier and more intuitive.
That said, if you’re using a different cloud data warehouse - like Snowflake, Redshift, or Databricks - you’ll likely find equivalent functionality. For instance:
Snowflake also supports
QUALIFYfor filtering based on window functions.Redshift requires using a CTE (Common Table Expression) or a subquery with
ROW_NUMBER.Databricks SQL has similar capabilities with window functions and filtering using subqueries.
Let’s break it down using BigQuery and touch on Snowflake as a comparison.
The scenario
Suppose you have a table called customers in BigQuery with the following data:
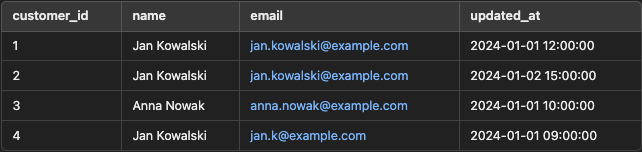
The goal is to remove duplicates based on the email column, keeping only the most recent record for each email, as determined by the updated_at field.
Solution 1: Using QUALIFY in BigQuery
Here’s how you can deduplicate data in BigQuery using QUALIFY:
SELECT
customer_id,
name,
email,
updated_at
FROM
customers
QUALIFY
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY updated_at DESC
) = 1;
How It Works:
ROW_NUMBER()assigns a unique number to each row within a group defined byPARTITION BY email.ORDER BY updated_at DESCensures the most recent record appears first in each group.QUALIFY ROW_NUMBER() = 1keeps only the first-ranked record for each email.
Result:

Snowflake, like BigQuery, supports the QUALIFY clause, so you can use the same query structure.
Solution 2: Using ROW_NUMBER Without QUALIFY
Not all data warehouses support QUALIFY. For instance, if you’re working in a SQL environment that doesn’t have it (like AWS Redshift), you can achieve the same result using a Common Table Expression (CTE):
WITH ranked_customers AS (
SELECT
customer_id,
name,
email,
updated_at,
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY updated_at DESC
) AS row_num
FROM
customers
)
SELECT
customer_id,
name,
email,
updated_at
FROM
ranked_customers
WHERE
row_num = 1;
This approach requires one extra step (creating a temporary ranking table) but achieves the same outcome.
Final thoughts
Deduplication is a common task, but modern tools like BigQuery and Snowflake make it a breeze. Features like QUALIFY simplify the process, while traditional methods using CTEs provide a solid fallback when needed.
So whether you’re working in BigQuery, Snowflake, or even AWS Redshift, you’ve got options for handling duplicates effectively. Try QUALIFY in your next deduplication task - it’s a small change that makes a big difference!